Training Data for
Computer Use Agents
High-fidelity human trajectories with full key, click, touch, and pixel traces for BC, reward modeling, and RL fine-tuning.
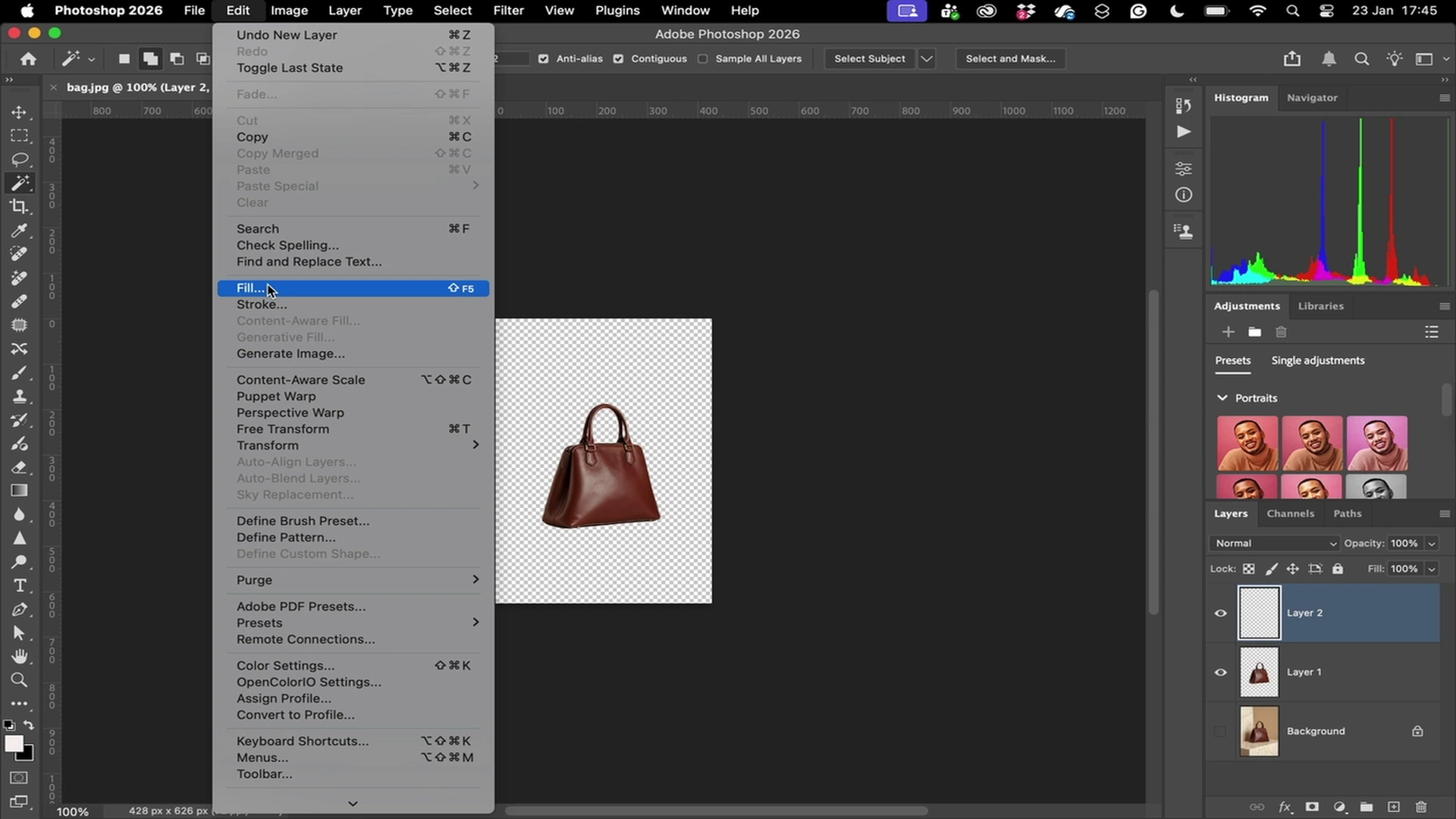
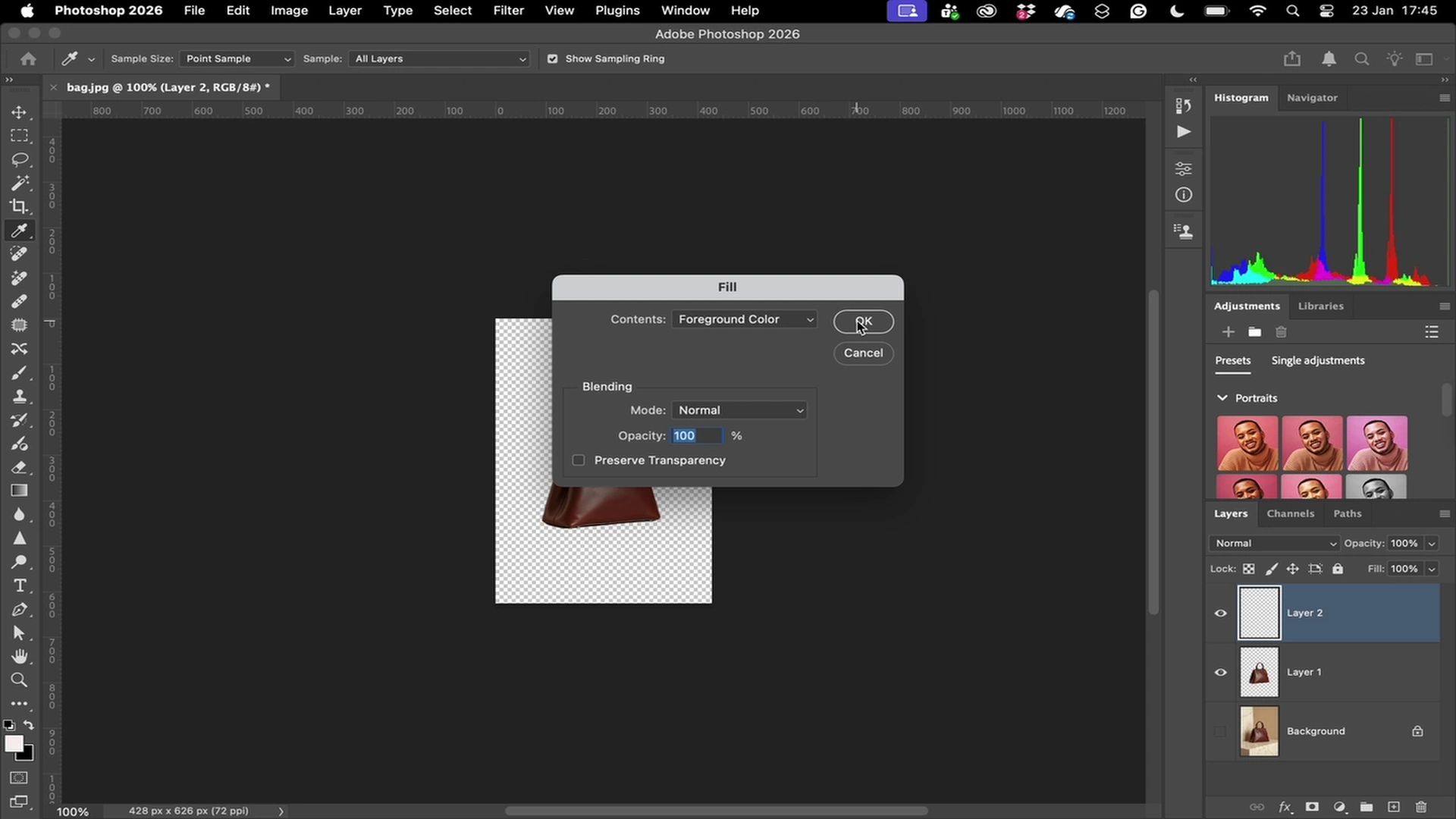
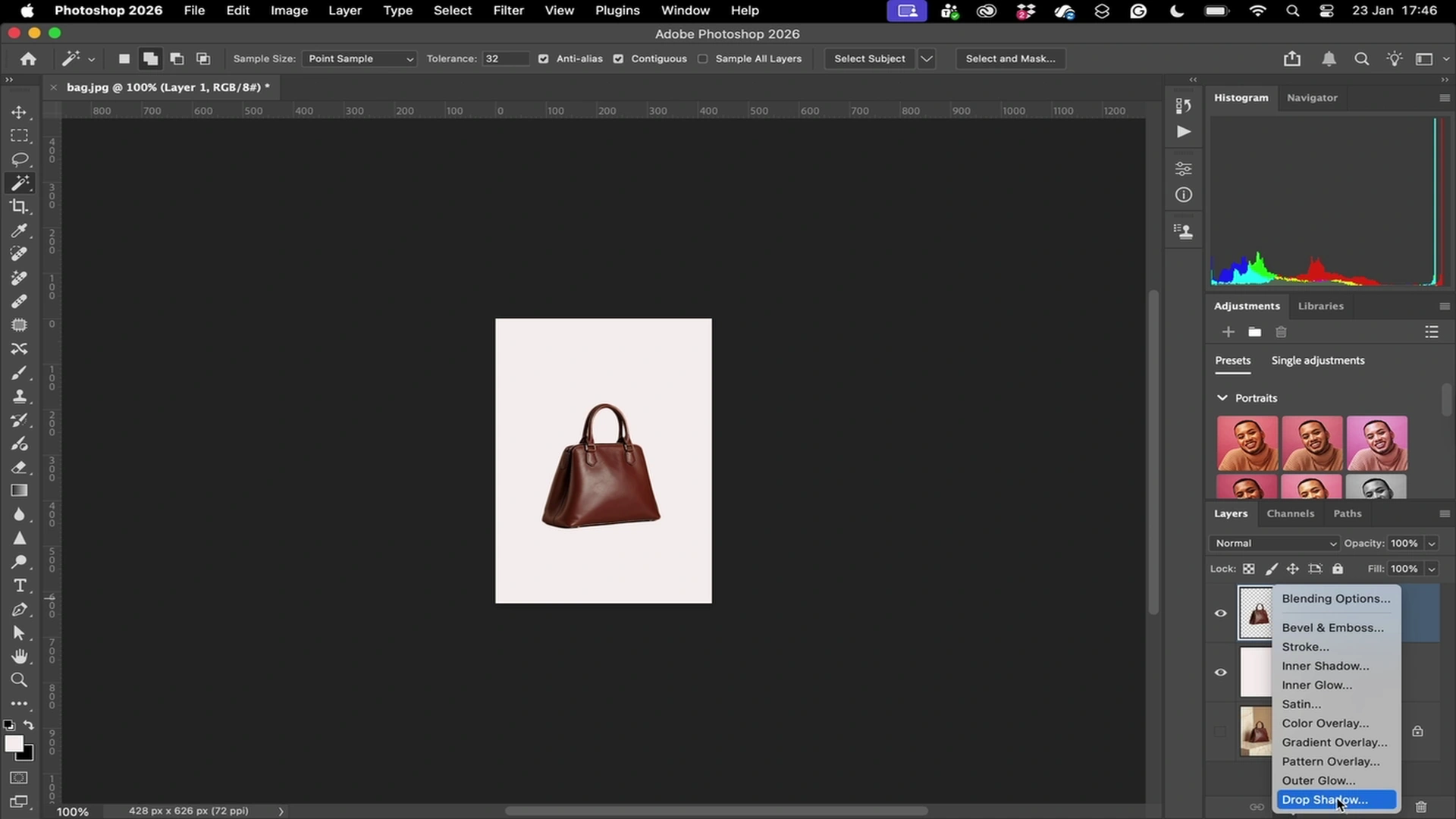
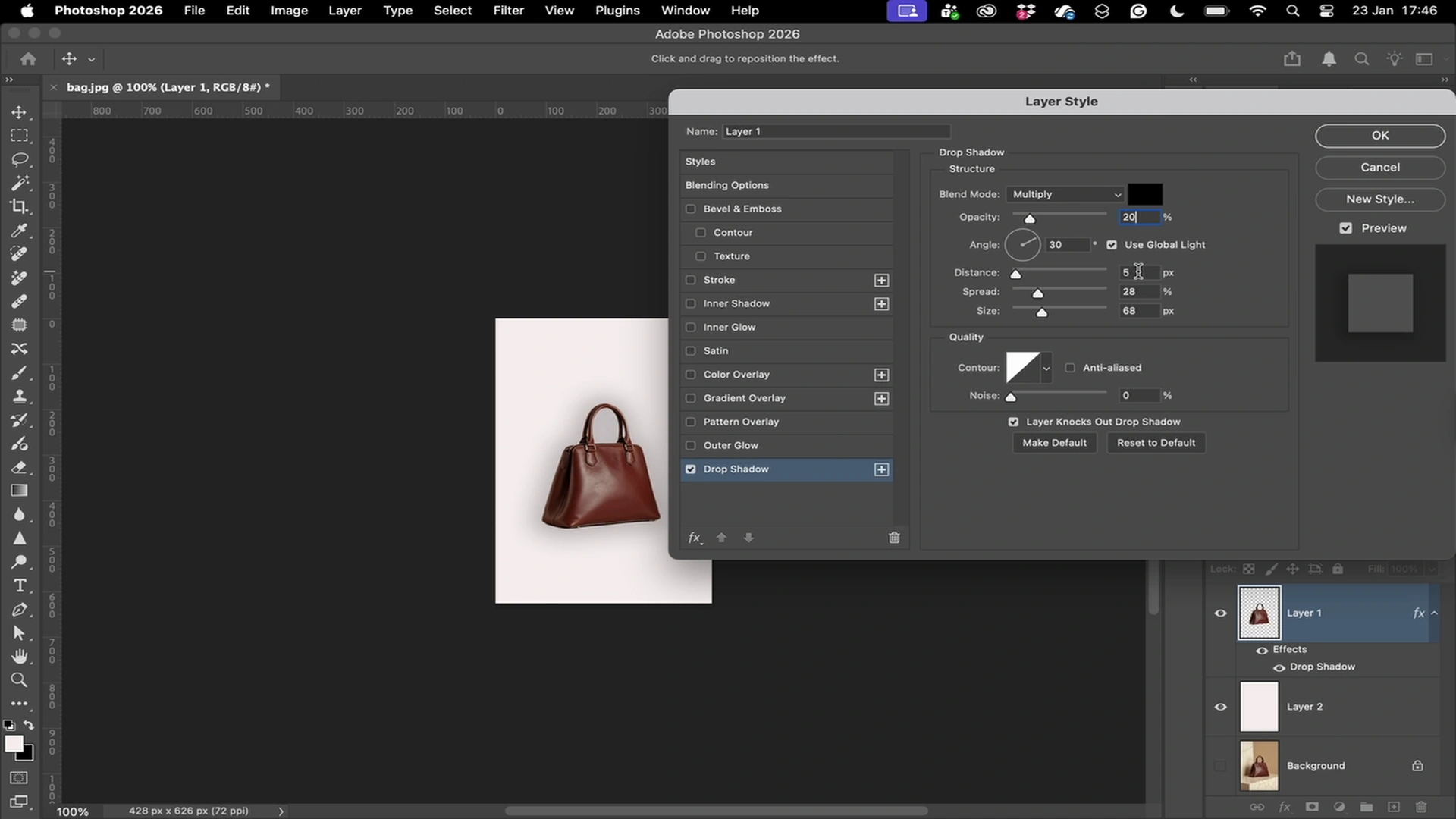
Used by teams developing
computer use agents
6M+ Actions Across 150+ Tools
Use off-the-shelf datasets or request custom data by task, domain, and environment.
About This Benchmark
This benchmark includes 2,500 questionscreated by subject-matter experts across multiple domains such as mathematics, humanities, and natural sciences.
Each question has a clear and verifiable solution, but requires advanced web retrieval and reasoning.
Methodology
- Evaluation:
Results are based on tests run using official Search MCP servers provided as an MCP tool to OpenAI's GPT-5 model using the Responses API. In all cases, the MCP tools were limited to only the appropriate web search tool. Answers were evaluated using an LLM judge (GPT-4.1).
- Cost Calculation:
Cost reflects the average cost per query across all questions run. This includes both the search API call and LLM token cost.
6M+ Actions Across 150+ Tools
Use off-the-shelf datasets or request custom data by task, domain, and environment.
Dataset Overview
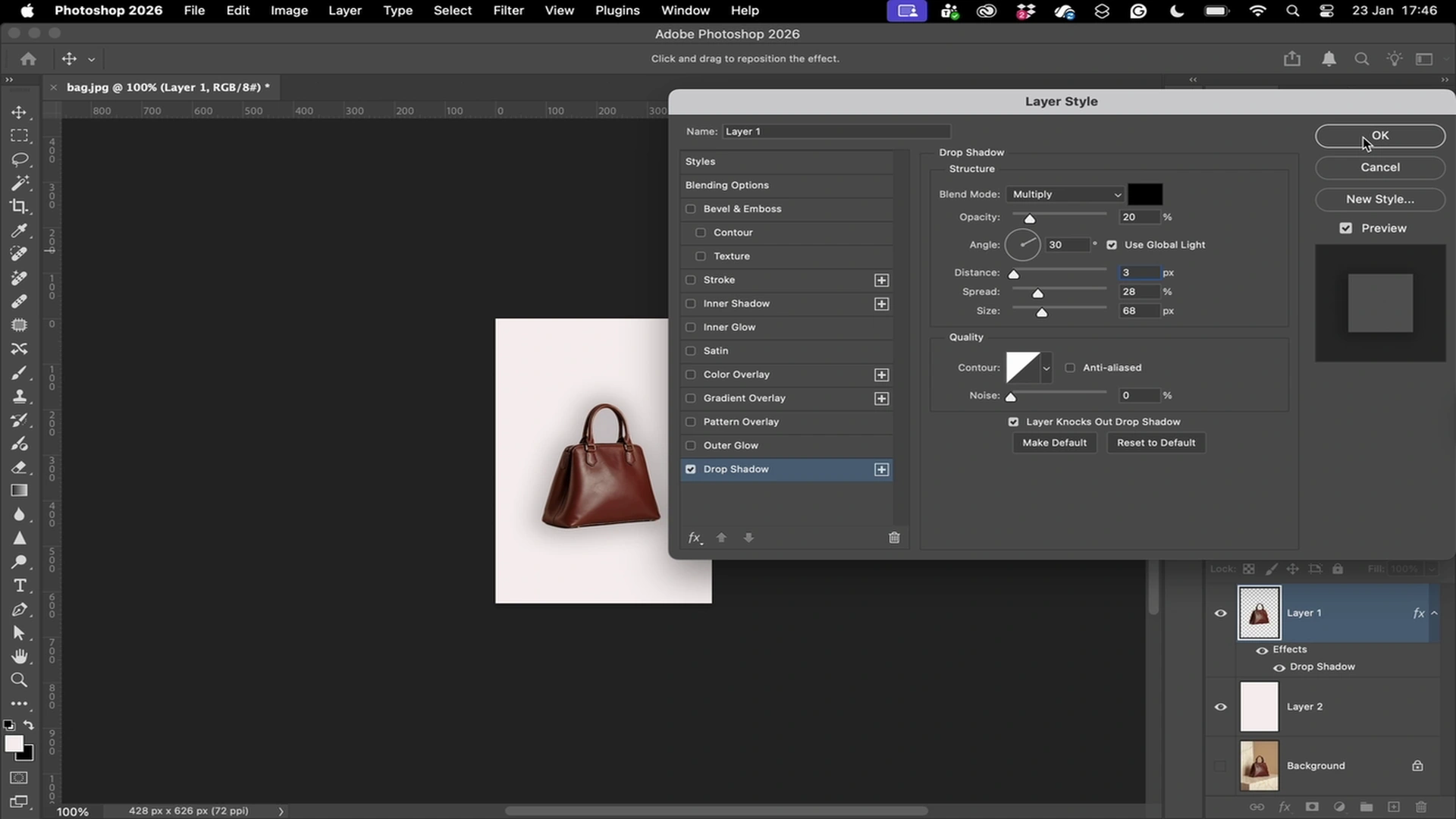
Every click, scroll, and keypress — logged at millisecond granularity.
Verifiable Computer Use Trajectories
Verifiable Data Quality
Every demo includes screen recordings and screenshots, enabling full traceability.
Action-Level Reasoning Data
Demonstrations include step-level actions paired with human decision context.
Built to Scale
We can create 10,000 hours of human demonstrations per week.
What Files You Get
Each demonstration includes a complete set of synchronized files for training and evaluation.
- Event Logs (.txt)
- Screen Recording (.mp4)
- Structured Trajectory (.json)
- Frames (.jpg)
Raw Data View
Pricing
Per-task pricing with clear visibility. Custom data priced by scope.
Licensing
Purchased datasets are owned by you and licensed for model training.
Privacy
PII is excluded by default. When present, explicit user consent is obtained.